
James Martin: We're using AI like a bazooka to swat flies
"The impact-to-benefit ratio is way off. And most people have no idea."
Despite being aware of the ethical problems around AI, many of us choose to use it anyway. And, like with many other online technologies, we do so with a constant unease and uncertainty. In this interview, I speak with James Martin to see if there are more ethical ways to use AI and how we should think about AI use on an individual level in the first place.
James is the founder of BetterTech, a publication on the impact of tech and a digital responsibility consulting firm. In this interview, we talk about:
The “all your base are belong to us” mindset behind big AI
Why so many people knowingly share sensitive data with chatbots
When using AI is like swatting a fly with a bazooka
How not to turn chatbots into doctors, therapists, or friends
What an “AI pescatarian” way of using technology looks like

When people say “AI is unethical” in that very black‑and‑white way, what are they usually referring to? And what might they be getting wrong?
“AI is unethical” is a huge claim. I’ve been working on this while creating my Responsible AI training, where I try to break that statement down into concrete risks, such as:
lack of transparency,
inaccuracy and hallucination,
bias,
social and environmental impacts,
and security risks.
Most of these problems cluster around what I call “big AI”, companies like OpenAI, Anthropic, and the big US tech platforms like Google, Apple, Meta, Amazon, and Microsoft. They behave as if our data belongs to them.
It’s like that old meme, “all your base are belong to us.” It’s literally that mindset applied to data.
The core ethical problem is this belief that they’re entitled to take:
all of humanity’s music, video, and written content,
plus everything we type into their systems,
and use it to train future models, usually by default, even on paid plans. You can opt out, but you have to go and find that setting, and most people never do.
They justify it by leaning on the grey area between fair use and reproduction: “We’re just learning from the data, not copying it.” The end result will only be quotes, and that’s fair use. But research has shown that at least one Claude model can reproduce the first Harry Potter book almost word‑for‑word. That’s not quoting anymore; that’s effectively reproducing the text, which directly contravenes US copyright law.
You see the same mindset in specific behaviour. For example, when OpenAI were building GPT‑4, their president Greg Brockman reportedly told the team to go onto YouTube, grab over a million hours of video, transcribe it with their Whisper system, and use that to train the next model.
People inside apparently said, “Doesn’t YouTube’s terms of service forbid that? Won’t Google sue us?” And the response was basically, “Do it anyway.”
Google didn’t sue, because they were doing something very similar themselves at the time to train Gemini. So you get this “two wrongs make a right” situation: everyone knows they’re in a grey zone, but no one wants to throw the first stone because they’re all doing versions of the same thing.
Anthropic is another example. Once they’d hoovered up most of the internet, the usual sources like web pages, YouTube, Reddit, they turned to books as a relatively untapped source of high‑quality data. The approach was what’s been called “destructive scanning”: you literally take physical books, tear out each page to scan it, and ingest it as training data. The books are destroyed in the process.
They’ve since settled a court case related to pirated copies of books and agreed to pay around $1.5 billion to hundreds of thousands of authors. The authors were thrilled; Anthropic can easily see it as a very affordable price for access to that many books. If both sides consider this a win, nothing will change.
So when people say “AI is unethical,” they’re often pointing to exactly this kind of thing: giant companies taking whatever data they can get away with, stretching or ignoring terms of service and copyright, and assuming that as long as they move fast enough, the legal and ethical questions will lag behind.
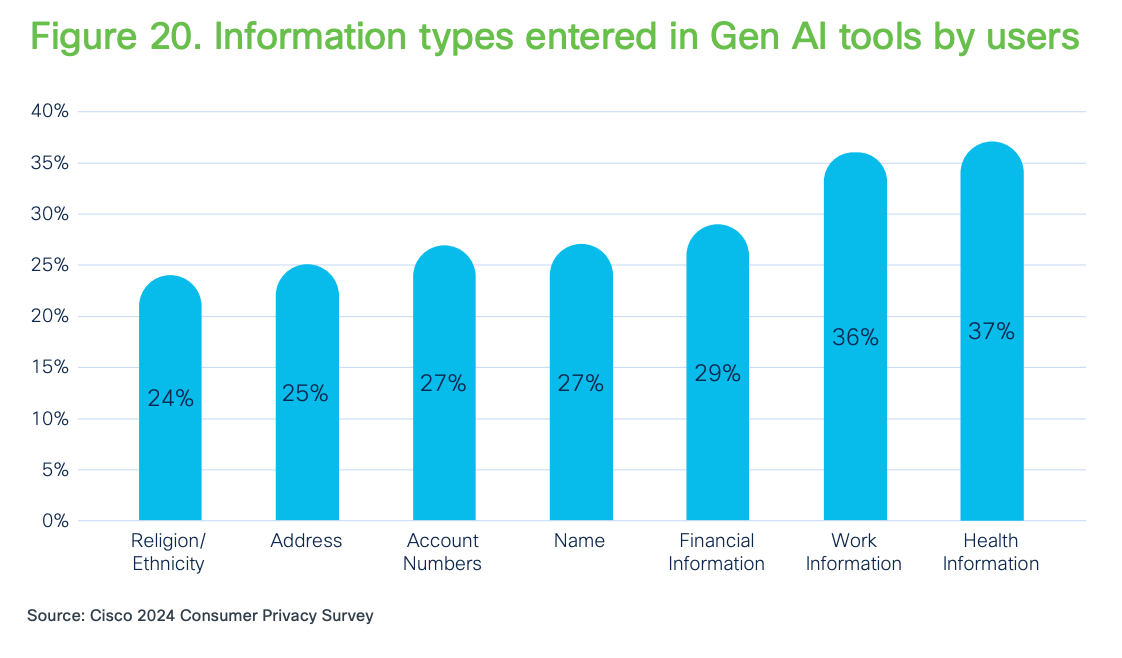
What worries me just as much is our behaviour as users. A Cisco survey found that nearly 30% of AI users have already given health or banking data to an LLM. People know there are privacy and security risks, but they still feed in highly sensitive information. That contradiction, seeing the problem and still participating in it, is a big part of why this all feels so ethically messy.
“All your base are belong to us — it’s literally that mindset applied to data.”
At least some part of that 30% will be people who are actually aware of ethics, security, and privacy problems, and still do it because the tools are so useful. How do you look at those trade‑offs?
I’m less interested in saying “you should” or “you shouldn’t,” and more in understanding what’s actually happening.
This technology is very new. People are still figuring out what it is and how to relate to it. But it has a lot in common with previous tech shifts: Amazon, Uber, and so on. These tools are incredibly handy. If something saves you time or effort, like writing, research, or admin work, many people will accept some level of risk, even if they know it’s not ideal.
I don’t think that’s irrational. It’s just not always informed.
“Do not treat these systems as doctors or therapists or oracles. They are predictive text engines with no understanding of harm, duty of care, or context.”
What’s the most common misunderstanding you see?
One worrying example is how people are using these tools for health and mental health. Some people paste their medical reports into ChatGPT: “The doctor said this. What does it mean? What should I do?” That’s extremely sensitive data, and then they treat the answer as if it were a doctor’s advice.
The core misunderstanding is that many people think an LLM works like a search engine: it goes off, finds the right answer in a database, and brings it back. That’s not what’s happening. It’s generating text word by word based on probabilities.
Because that’s invisible, people assume it’s telling the truth. In reality, it often hallucinates – and will give you different answers if you ask the same question again.
So one of the simplest ethical pieces of advice I can give is: do not treat these systems as doctors or therapists or oracles. They are predictive text engines with no understanding of harm, duty of care, or context.
How much responsibility do you think sits with the individual user?
This is where regulation is interesting. If you look at the EU AI Act – which is often described as the most advanced AI law in the world – individual users are given essentially no responsibility.
The law focuses on:
providers,
deployers,
importers,
and a few other categories. It’s about companies and organisations, not people at home on their phones. Even employees are only partially covered, and more through their employer’s obligations than their own.
So under that framework, someone using ChatGPT at home has no formal responsibility. You could argue about whether that’s right or wrong, but legally, that’s where we are.
For companies, this has big implications. If your staff, as users, have no legal responsibility, then you need internal rules and governance. The Samsung case is a good example: In 2023, a Samsung employee uploaded confidential code to ChatGPT. Management were furious, and temporarily banned usage of the chatbot, including threats of potential employment termination for contraventions. When they allowed it again, it was with very strict conditions, underlining the fact that those rules should have been there in the first place.
So in a corporate context, if the law doesn’t put responsibility on users, companies have to.
So what should everyday users feel responsible for? Is this like the environmental footprint question – how much is really on the individual?
It’s very similar.
When I talk about this, I try not to guilt people, because it’s not their fault that large language models are so impactful. These tools were dropped into people’s laps, often for free.
The bigger issue is structural: data centres, hardware, software – the three pillars of green IT – and the way generative AI uses GPUs instead of CPUs. GPUs are far more energy‑intensive, and they were originally designed for video games, not AI. So we’ve essentially hacked gaming hardware into a global AI infrastructure.
Because of this, generative AI is much more impactful than any IT product we’ve used before.
So I encourage people to ask a few simple questions:
Do I really need AI for this? The number one use of LLMs right now is replacing a web search. Instead of looking something up, people ask the model. Do you really need a giant model to find a pancake recipe?
Is there a simpler alternative? Can you use a normal search, a dictionary, your own knowledge?
I sometimes use the image of using a bazooka to swat a fly. If you use a huge model for something trivial, the impact-to-benefit ratio is way off. And most people have no idea that’s what they’re doing.
On top of that, the big AI companies are not transparent about their impacts. They might say “one prompt uses this much water,” but they don’t give enough information to properly assess the full footprint. It’s a classic pattern: the more you hide, the more people suspect you’ve got something to hide.
Technically, it’s also very inefficient. Some estimates suggest big labs are only using about 20–30% of each GPU’s compute capacity. The rest is wasted. There’s a white paper arguing that if we could push that to around 60% and keep GPUs in service for three years instead of one, we’d only need about half the GPUs we’re currently building data centres around.
So for individuals, I’d say:
Don’t feel personally responsible for fixing all this.
But do be thoughtful about when you use AI, what for, and which tools you choose.
And remember that smaller, more focused models often exist and are far less impactful than the giant ones… and they’re often open source, so free!
We’ve covered a lot of the dark side. What’s there to be optimistic about? What, if anything, excites you about this technology?
I am optimistic, but not about the current “bigger is always better” race.
Cory Doctorow wrote a piece where he said he’s looking forward to the AI bubble bursting. I agree. When the hype calms down, we’ll be left with the things that are genuinely useful:
smaller, more specialised models,
tools that can run locally on your phone or laptop,
systems that don’t always need the cloud,
and AI that is right‑sized to the problem.
A lot of the most useful AI for the planet isn’t generative at all, it’s predictive: forecasting storms, optimising energy grids, reducing waste in data centres. One example I love is a project that puts small, solar‑powered sensor boxes in rainforest trees. A tiny algorithm listens for the sound of chainsaws and alerts the authorities to illegal logging. That’s AI used well.
So I’m not anti‑AI. I’m against huge, opaque, resource‑hungry systems being used for everything. I’m very much in favour of smaller, pragmatic systems that solve real problems, ideally running on renewable energy.
“I try to use my own brain first; only use AI when it genuinely helps; and when I do, choose smaller, more efficient models wherever possible.”
Last question: what do you make of people who try to “opt out” of AI? Is that a meaningful stance?
I get asked if I’m an “AI vegan”, someone who refuses to use it at all. I usually say I’m more of an AI pescatarian.
I try to:
use my own brain first;
only use AI when it genuinely helps;
and when I do, choose smaller, more efficient models wherever possible.
There are already tools out there that try to be “green ChatGPTs”: leaner, more transparent, built with impact in mind.
Completely opting out is getting harder, because AI is being baked into everything. You see “Use AI” buttons everywhere. But you can still:
resist using it by default,
avoid feeding it sensitive or other people’s data,
choose smaller tools over giant ones,
and never treat it as a doctor, therapist, or source of truth.
For me, that’s what using AI more ethically looks like at an individual level.
James’ BetterTech Blog
James’ Responsible AI & Frugal AI training courses